Monitorando Logs do AWS Lambda em tempo real utilizando AWS CloudWatch, Elasticsearch services e Kibana (DEMO)
Salve salve devs! O título é bem auto-explicativo, mas se tu não faz ideia do que eu to falando, vamos por partes então:
Salve salve devs! O título é bem auto-explicativo, mas se tu não faz ideia do que eu to falando, vamos por partes então: | ||
Entendendo o problema | ||
Imagine o seguinte cenário: você precisa monitorar logs de funções lambdas para conseguir entender melhor onde e quando elas estão quebrando, e gerar alguns insights para entender os motivos disso. | ||
De cara, você não sabe nada de como mexer no console da AWS e não sabe por onde começar a desenvolver isso. Aí você começa a ver soluções com mensageria (AWS SNS), começa a ver streaming de dados (AWS Kinesis), e nada da certo. Mas calma lá -- SEUS PROBLEMAS ACABARAM -- Eis-me aqui pra te ajudar. | ||
Vamos começar visualizando a parada. | ||
| ||
O que você quer fazer, em suma, está aí em cima. Certo!? Você precisa de algo que pegue os dados de log das lambdas, processe isso e que jogue pra um dashboard. Simples assim. | ||
Após anos de pesquisa, eu encontrei a solução pra esse problema (na real foram bastantes testes mesmo, mas longe de anos né). | ||
E a solução pra esse problema, foi utilizar o ELK stack. Se tu não sabe o que é isso, eu não vou explicar aqui, pois o foco é a mão na massa. Mas da uma olhada no próprio site deles. | ||
"ELK" é o acrônimo para três projetos open source: Elasticsearch, Logstash e Kibana. O Elasticsearch é um mecanismo de busca e análise. O Logstash é um pipeline de processamento de dados do lado do servidor que faz a ingestão de dados a partir de inúmeras fontes simultaneamente, transforma-os e envia-os para um "esconderijo" como o Elasticsearch. O Kibana permite que os usuários visualizem dados com diagramas e gráficos no Elasticsearch. | ||
Resumindo, esses caras foram feitos pra analisar logs. | ||
Implementar eles, é uma tarefa simples e não. Como assim? Bom, na verdade pra fazer algo simples, é simples, mas pra escalar, é mais complicadinho. Entendeu né!? | ||
O bom da parada, é que a AWS tem implementado um serviço que já sobe todo (sem logstash na real) o ELK stack pra nuvem: o Elasticsearch Services. Esse carinha sobe um domínio Elasticsearch e já nos concede o kibana junto. | ||
E então, você visualiza o que quer implementar (é o que vamos fazer aqui nesse tutorial/demo): | ||
| ||
Certo, você já conhecia do CloudWatch Logs né? E inclusive, assim como eu, talvez tenha tentado utilizar o CloudWatch Insights pra resolver o problema e tenha se frustrado. Mas enfim, vamos usar ele para enviar os logs pro Elasticsearch e visualizar com Kibana. Dale! | ||
Vamos utilizar o seguinte passo a passo: | ||
| ||
Criando uma subscrição de elasticsearch em um Log group | ||
Vamos lá! | ||
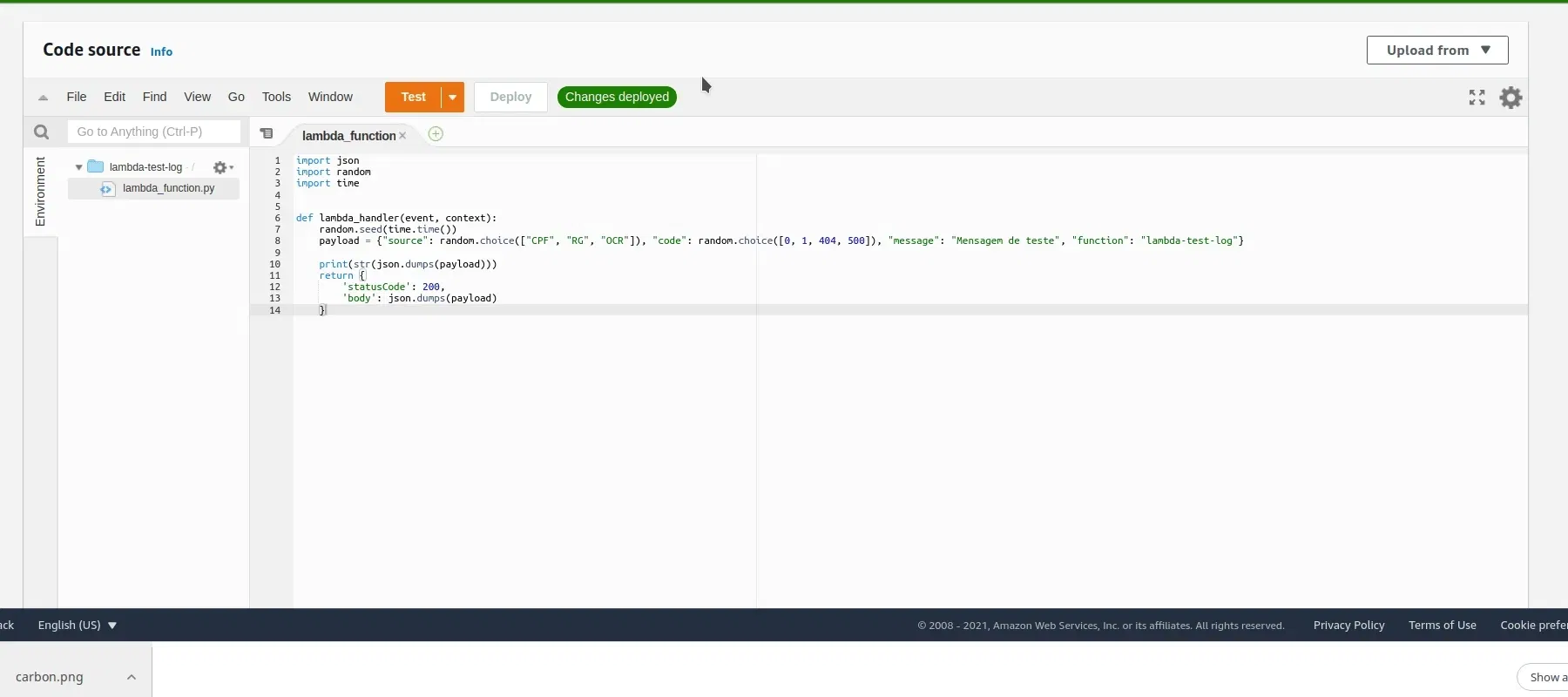
1. Criando lambda de teste | ||
Primeiramente vamos criar uma lambda de teste. Para isso, basta acessar o AWS Console e pesquisar ou clickar em "Lambda". | ||
| ||
Na interface que abrir, para criação de lambda. Vamos clickar em "create function", colocar o nome, e selecionar em que linguagem vamos escrever. (No nosso tutorial, vamos usar Python <3). | ||
| ||
Após criá-la, precisamos criar outputs, isto é, criar os nossos logs simulados. Para isso, podemos usar de prints ou console.log da vida. | ||
| ||
Temos mensagens em json como outputs de log. E possuímos alguns parâmetros para visualizarmos mais futuramente, como "source", "code" e "message". | ||
| ||
Para testar a Lambda, basta apertar em test, e setar uma função hello world de teste. Toda vez que ela executar, códigos e sources aleatórios são gerados, ou seja, geramos um log fictício para a função :D | ||
| ||
Com nossa lambda de teste criada, vamos para o nosso próximo passo, que é substâncial: a criação do domínio no Elasticsearch Service. | ||
2. Criando domínio do Elasticsearch | ||
Step 1: Primeiramente procure por "Elasticsearch Services" no console. Clique em "Create new domain" e depois vamos pegar um "development and testing". (Por fim "next" obviamente). | ||
| ||
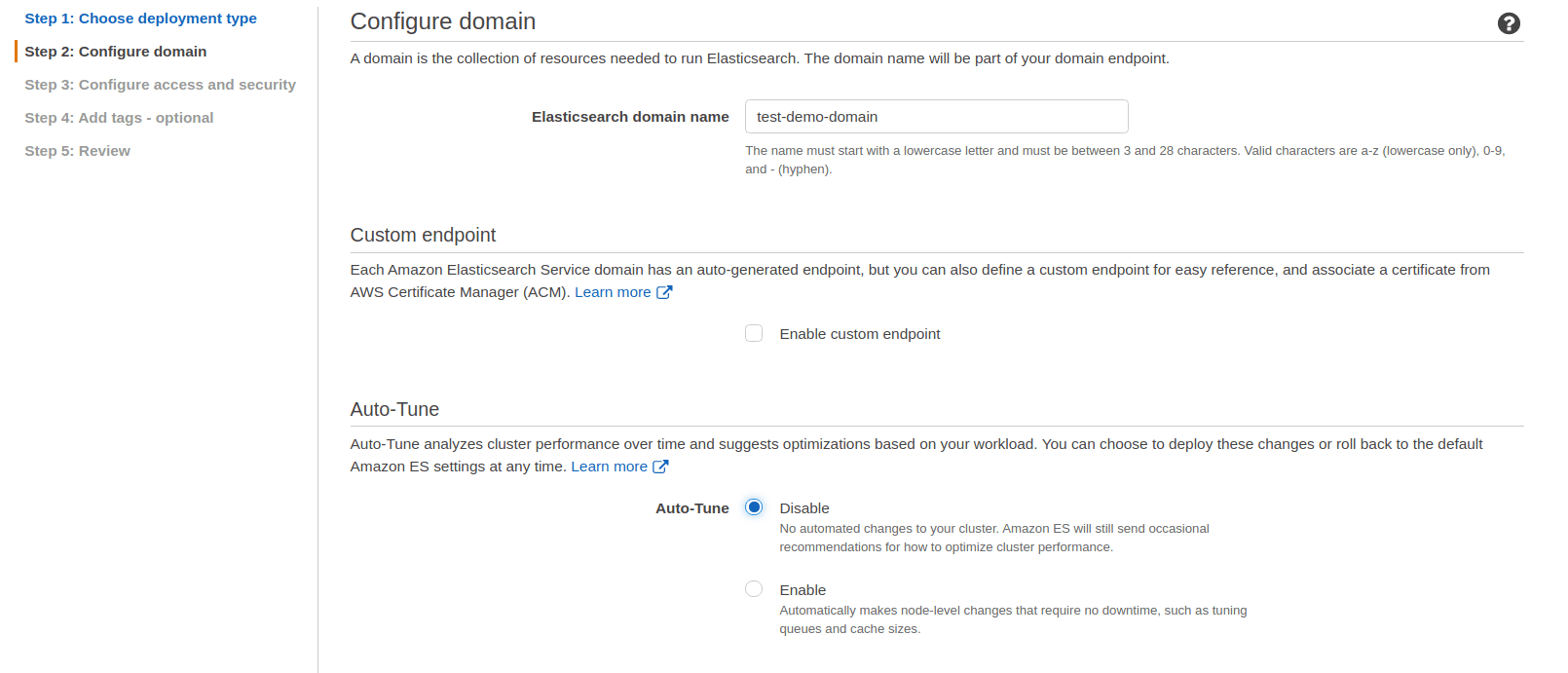
Step 2: Na aba seguinte defina o nome do domínio; deixe desmarcado o custom endpoint; desabilite o autotune; e selecione uma instância menos robusta (mais barata). | ||
As duas opções finais (Data nodes storage - Dedicated master nodes), pode deixar default. | ||
Segue prints de como vai ficar: | ||
| ||
| ||
Step 3: Para configurações de acesso a rede (isso daqui vai nos habilitar a conexão correta com Kibana), você pode configurar uma VPC. Como é muita mão, vamos deixar como Public access. | ||
| ||
Os posteriores - Fine-grained access control, SAML auth para kibana e opção de cognito - nós vamos deixar off. E então em Access policy, nós vamos habilitar o nosso próprio IP para acessar o kibana. | ||
| ||
Step 5: depois de ter clickado em next, após adicionar o ip, o passo 5 é muito complexo. | ||
| ||
Step 6: Aqui você pode conferir se está tudo ok, e finalizar com um "confirm". | ||
Ah, não esquecendo que demora uns 10min pra subir o domínio inteiro. Então dê uma aguardadinha. | ||
3 . Criando uma subscrição de elasticsearch em um Log group | ||
Vá até o CloudWatch, e selecione Log groups. Depois selecione o log group que tem o nome da função lambda que criamos lá no passo 1 (lambda-test-log). E então em actions, seleciona um subscription filter. É aqui que vamos fazer o cloudwatch enviar os dados para o domínio do elasticsearch. | ||
| ||
Selecione o cluster do Elasticsearch que criamos | ||
| ||
Depois de selecionarmos o cluster, o AWS nos pede uma role que executará uma lambda que ele mesmo cria pra nós. Essa lambda é responsável por de fato enviar os dados do clouwatch para o ElasticSearch. | ||
Vamos criar um IAM Execution Role para ela. Para isso, vá até o IAM, navegando pelo console da AWS e selecione "Roles" no menu da esquerda. | ||
| ||
Após clickar em create role. Na próxima tela, vamos em AWS service > Lambda. | ||
| ||
As permissões que precisamos estão dentro de AmazonESFullAccess. Selecionamos a permissão, e depois de next, colocamos o nome e por fim "create role". | ||
| ||
Depois disso, podemos retornar à criação da subscrição no CloudWatch. Lá basta atualizar as roles, e selecionar a que acabou de criar. | ||
Mas antes do próximo passo, vamos lembrar a estrutura do log de teste que criamo | ||
START RequestId: d528ed51-c99e-4891-a75a-cc12d4f00f3f Version: $LATEST{"source": "CPF", "code": 1, "message": "Mensagem de teste", "function": "lambda-test-log"}END RequestId: d528ed51-c99e-4891-a75a-cc12d4f00f3f | ||
Precisamos apenas da linha que nos retornou o json. Então vamos criar um filtro. Caso não criarmos um, todos os logs e todas as linhas vão ir pro elasticsearch. | ||
E esse filtro pode ser simplesmente um "{$.source = *}". | ||
| ||
Após isso, vamos testar o filtro que criamos, em "Test pattern". | ||
| ||
Show! Com o filtro pegando apenas o json, podemos clicar em "start streaming". | ||
Feito! Agora o cloudwatch está fazendo stream dos logs (do log group) para o "test-demo-domain" no Elasticsearch Service cluster. | ||
4. Descobrindo os dados no Kibana | ||
Voltando no Elasticsearch Services, temos acesso a um link direto para o kibana, que subiu junto no cluster. Bora lá. | ||
| ||
Vá até sua Lambda function, e clique algumas vezes em "teste". Isso vai fazer com que alguns logs sejam gerados. | ||
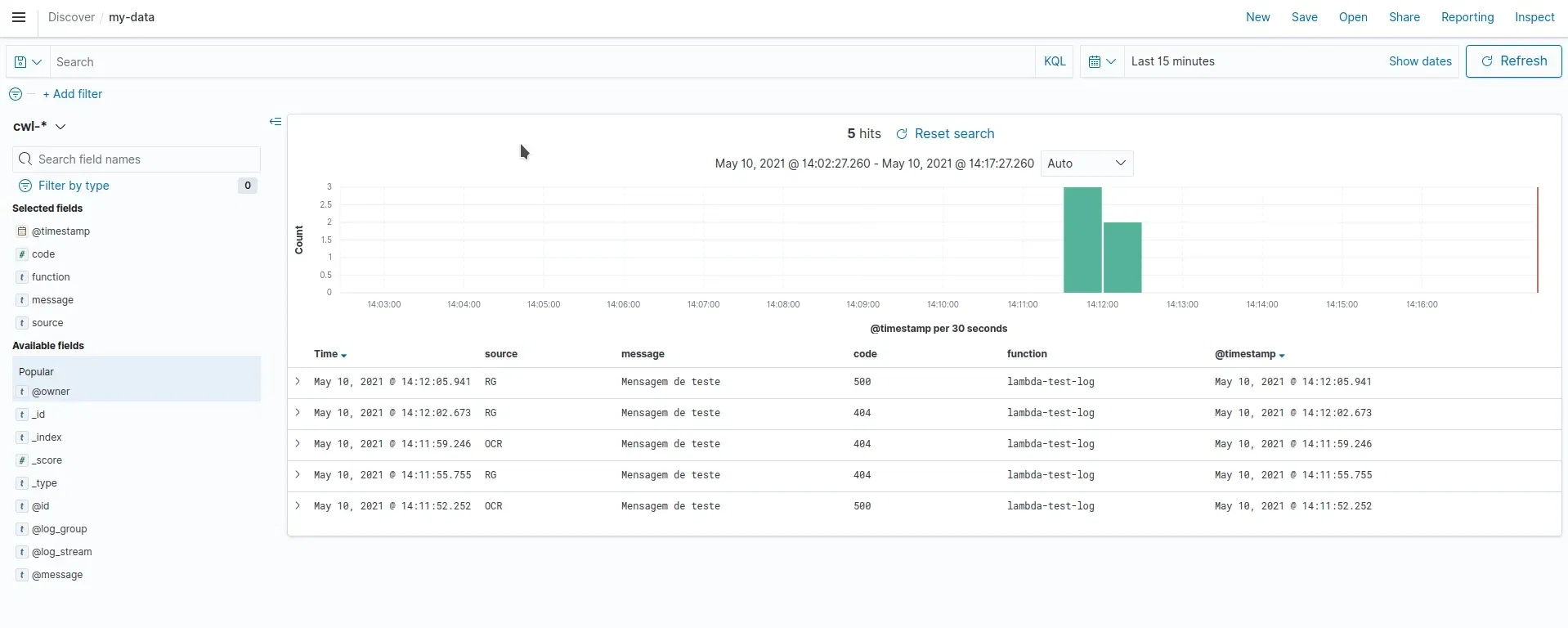
Para visualizarmos nossos dados no kibana, precisamos encontrar os nossos dados. Então, primeiramente vamos em discovery, no menu da esquerda. | ||
| ||
Agora precisamos criar um index pattern. Isso é para que a gente consiga pegar os nossos dados. | ||
Por padrão, o clowdwatch nos envia os dados com inicio "cwl-data", por exemplo: "cwl-2021.05.10". Então vamos criar nosso padrão de índicve como sendo "cwl-*". | ||
| ||
Depois de selecinar o padrão, clickamos em Next Step > e adicionamos um timestamp para lidarmos com tempo (isso vai nos ajudar a criar séries temporais). | ||
| ||
Se visualizarmos, podemos constatar que os dados vindos do json já foram bem saparadinhos e tá tudo bem bonitinho. | ||
| ||
Agora, só resta criar visualizações e gerar dashboards | ||
5. Criando visualizações e dashboards no Kibana | ||
Com os dados já descobertos, podemos visualizá-los ao selecionar "discovery" novamente (no menu da esquerda). Se os dados não aparecerem de imediato, aumente o intervalo de tempo, e verás os dados de teste que enviou. | ||
| ||
Como eu sei qeu tu é uma pessoa bem antenada nas coisas, já deve ter se ligado que tem muitos dados "inúteis" no meio dos logs. Para trabalhar apenas com os dados que solicitamos, podemos criar um "data table" com esses campos de interesse. | ||
| ||
Com o data table filtrado bonitinho, podemos criar nossas visualizações. | ||
| ||
Vamos fazer uma timeserie, visualizando a contage de códigos ao longo do tempo, por source. Segue o gif pra entender como fazer, que depois eu explico melhor k. | ||
| ||
OK, temos um problema. Como podemos visualizar o source? | ||
Pensa comigo, visualizamos o tempo no eixo X, visualizamos o total de códigos no eixo Y, e na "dimensão" das cores, visualizamos qual código estamos falando (400, 500, etc); Como podemos visualizar o source nesse contexto? | ||
Para resolver isso, vamos criar um "control"; | ||
| ||
Com o filtro criado, vamos colocar o nosso índice e adicionar o "source". | ||
| ||
E não esquecendo de desabilitar o "multiple select", para que um source seja selecionado por vez. | ||
| ||
Com as duas visualizações criadas (e não se esqueça de salvá-las), vamos adicionar elas em um dashboard. | ||
| ||
Beleza, e agora vamos adicionar as nossas duas visualizações que criamos. | ||
| ||
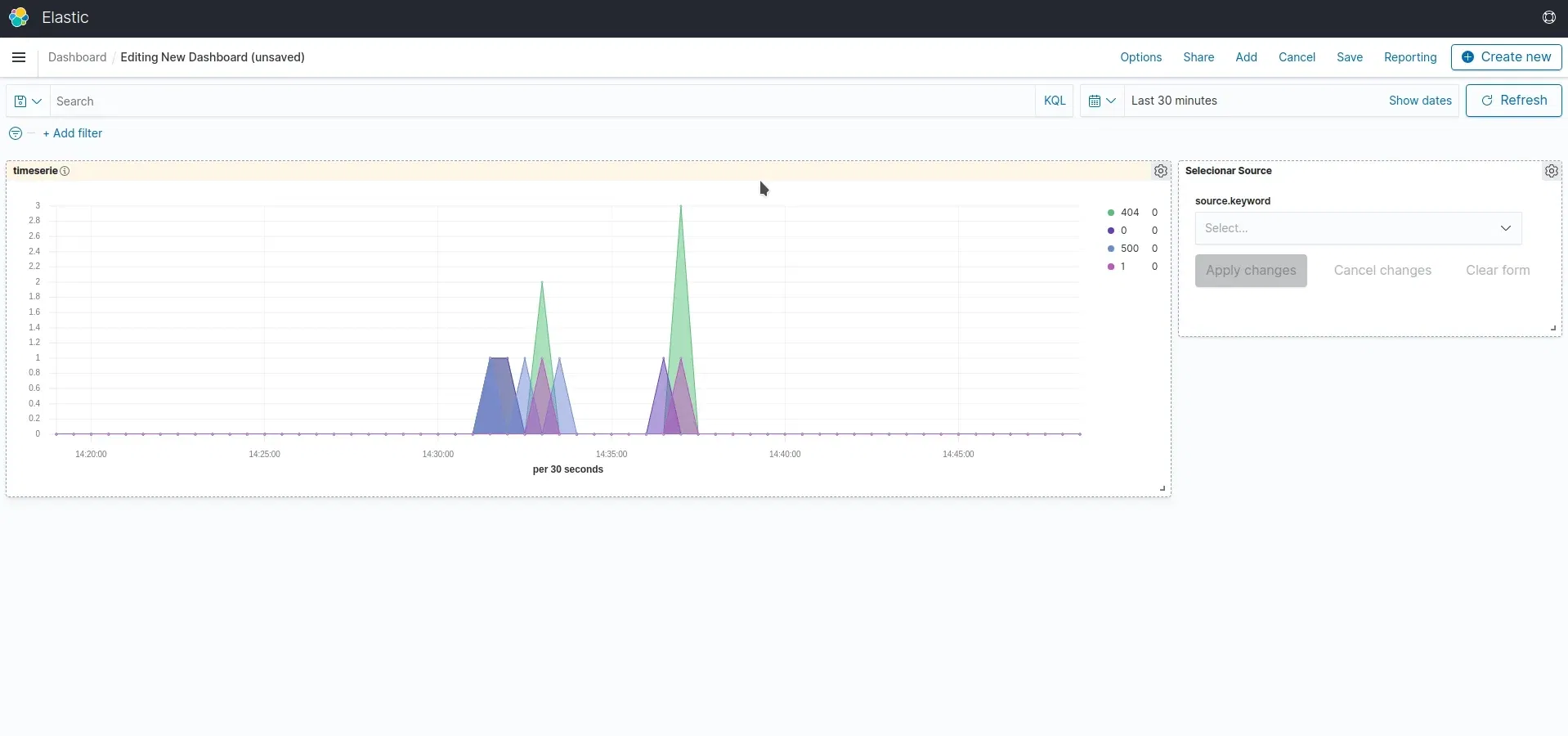
E ok! Depois de dar uma organizadinha nas visualizações, podemos acompanhar a contagem de códigos de log, ao longo do tempo, e selecionar o "source". | ||
| ||
Feitoria! No tutorial de hoje, criamos esse fluxo: | ||
| ||
E conseguimos visualizar logs de funções lambda, utilizando elastic search e kibana. | ||
Até a próxima gurizada. |