Qual é o maior time do Rio Grande do Sul? (Com Ciência de Dados)
Internacional x Grêmio (GRENAL) é uma das maiores rivalidades do futebol mundial. Semelhante a Boca Juniors x RIver Plate (Buenos Aires, Argentina). Lazio x Roma (Roma, Itália) e Barcelona x Real Madrid (Espanha) kk.
| ||
Disclaimer: Esse artigo é um tutorial de ciência de dados. Os conjuntos de dados utilizados para essa análise podem ser encontrados na Wikipédia: Wiki Inter e Wiki Grêmio, e o Código completo pode ser encontrado aqui no github. | ||
Internacional x Grêmio (GRENAL) é uma das maiores rivalidades do futebol mundial. Semelhante a Boca Juniors x RIver Plate (Buenos Aires, Argentina). Lazio x Roma (Roma, Itália) e Barcelona x Real Madrid (Espanha) kk. | ||
Hoje nós vamos utilizar das técnicas de ciência de dados pra comparar os dois clubes e ver qual é o maior, usando como critério o número de campeonatos ganhos. Como existem vários tipos de títulos, vamos olhar apenas para os torneios mais expressivos do Rio Grande do Sul, Brasil e América do Sul. | ||
Extração | ||
Após carregar os pacotes padrões pra um projeto de data science (pandas, numpy e etc) que tu já sabe, estamos aptos a começar a brincadeira. | ||
Para carregar datasets direto da web, existe o método read_html() do pandas. | ||
Usando esse método em sites que contenham mais de uma tabela (como geralmente é o caso da Wikipédia) uma lista contendo todas as tabelas vai ser retornada. Então, a gente precisa especificar qual vamos usar. Se tu abrir o link lá da Wikipédia, vai ver que é a primeira lista a que interessa, ou seja, a [0]. | ||
| ||
Com os datasets carregados, vamos dar uma olhada em como os dataframes ficaram. Aqui a gente usa o bom e velho .head(). | ||
| ||
Data Exploration | ||
Antes de mais nada, vamos remover as 'Unnameds', que eram os divisores das tabelas (multinível). Daí vamos de .drop(). | ||
| ||
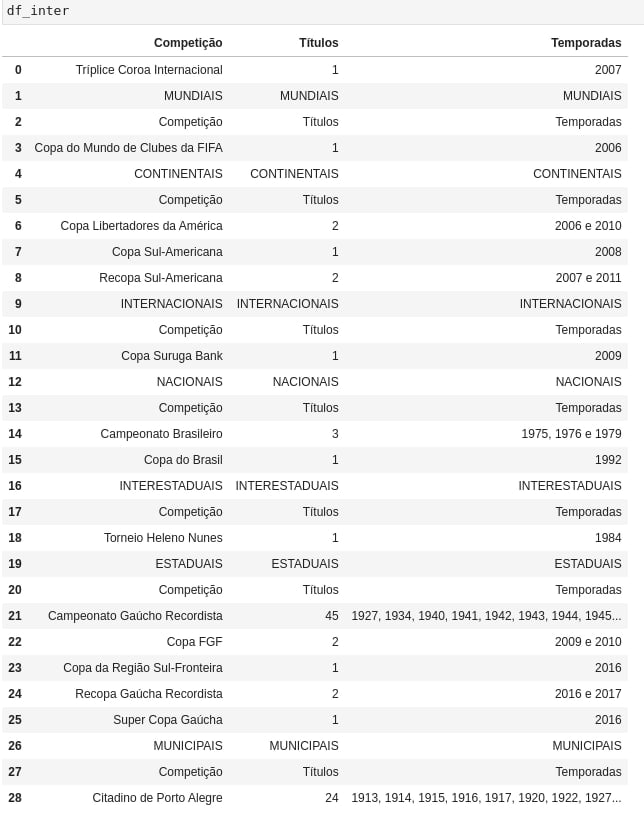
Então, cada dataframe fica dessa maneira: | ||
| ||
| ||
Data Cleasing | ||
| ||
Certo, cada um deles possui um monte de probleminhas, por conta dos dados tabulados da Wikipédia terem vários separadores (uns subtitulos dizendo qual categoria o campeonato pertence). | ||
Então, vamos selecionar apenas as linhas que contenham os torneios que a gente quer ver. Isso elimina o erro dos "INTERESTADUAIS", "ESTADUAIS" e etc, e também a gente já filtra pras competições que nos interessam. | ||
Os torneios que a gente quer ver são: | ||
| ||
Para fazer isso, vamos criar uma lista contendo todos os valores que correspondem a esses campeonatos aí (removendo os que dizem "recordistas" pelo internacional), e testar se a linha da competição corresponde a algum dos campeonatos, utilizando o .isin() | ||
| ||
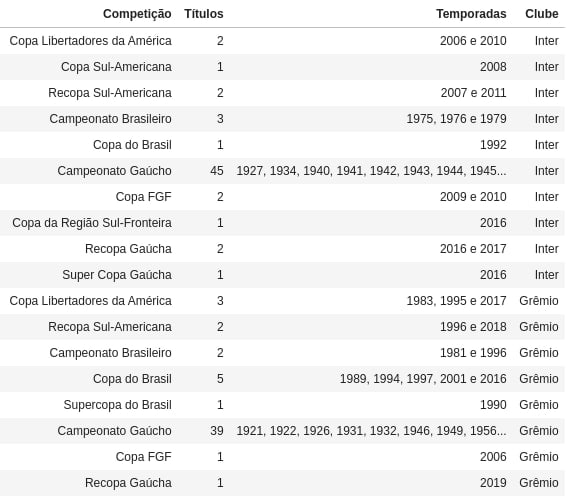
E pra fins didáticos, vamos criar uma coluna em cada dataframe pra indicar o time que ele corresponde. | ||
| ||
Merge Data | ||
Com os dados limpos e demarcados, vamos uni-los para ser mais facil analisá-lo. Podemos fazer isso com um simples .append(). | ||
| ||
Vendo o dataframe que temos agora, é essa belezura aqui: | ||
| ||
Algumas tramoias | ||
O interessante dessa área, é que da pra fazer uma coisa de várias maneiras. Existem as mais recomendadas, e as que funcionam também kk. | ||
| ||
Data Viz | ||
Um dos pontos mais importantes de um projeto de data science (independente do tamanho dele) é a visualização dos dados, que realmente explique o problema que o próprio projeto se propôs em responder. | ||
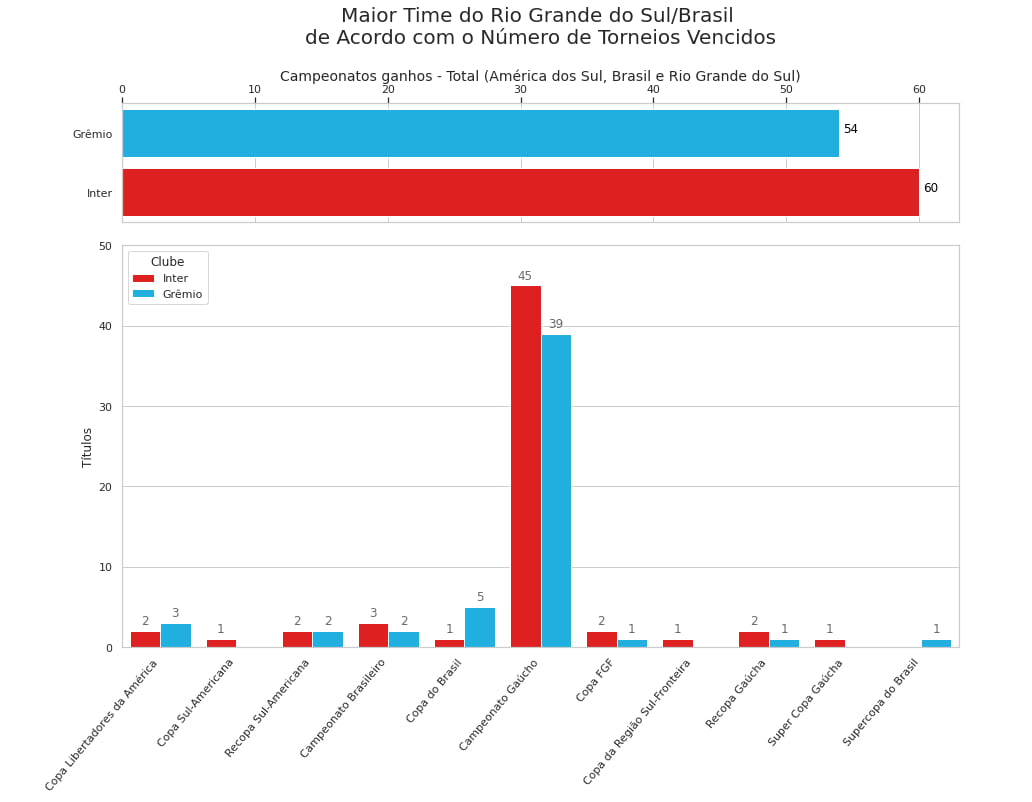
No nosso caso, queremos visualizar qual clube tem o maior número de títulos totais, ao mesmo tempo em que comparamos cada título entre os clubes. | ||
Lembrando que o código completo desse notebook, incluindo o código pra geração desse gráfico encontra-se aqui. | ||
| ||
Conclusão | ||
Com a visualização dos títulos mais expressivos, pro contexto gaúcho, vemos que o internacional tem mais títulos totais que o Grêmio. Porém, o Grêmio tem mais Copa do Brasil. | ||
Então, no contexto do Rio Grande do Sul, S.C. Internacional é o maior clube de futebol! | ||
|