It doesn't have to be messy with Firestore
I've been developing iOS apps for about 8 years now, and across those years, I saw myself dealing with mobile database platforms a few times. In my opinion, Firestore is the most robust and scalable platform.
It doesn't have to be messy with Firestore - Part 1
I've been developing iOS apps for about eight years now, and across those years, I saw myself dealing with mobile database platforms a few times. In my opinion, Firestore is the most robust and scalable platform out there.
Database platforms such as Realm Sync and Firestore have democratized a lot of the app development game. They offer a way more straightforward approach to setting up and deploying your database on the cloud. However, this pursuit to ease the mobile app development landscape came with some cons.
Database code everywhere
I feel that many of these mobile database platforms were caught in the trap of advocating the most straightforward use of their solutions to make it clear for the developers that it's so easy that you'd need an extra call to make your app to persist the data.
They're doing their job correctly, and it should be the developer's job to balance how to implement things to avoid having database code everywhere in their codebase. However, that doesn't seem to be the case for many projects.
I can see why it happens, those solution's SDKs are just like sugar for us. They seem so easy and inoffensive that you start using them all around, and then when you least expect your codebase has grown a lot, and these inoffensive sweet database calls all over your app are now a big trouble that might be causing user-facing issues or just became a massive pain for a platform/database migration.
After experiencing this issue in a big project, I decided to explore approaches to take advantage of a database platform while keeping all the database-related code isolated from the application code to start a new project.
Before diving into the idea behind isolating BaaS code from the application code, I want to praise the Firestore team 🎉. They built a great product, and the maintainers of the iOS SDK repo were always super eager to help me clarify things when I was exploring this approach.
The solution
Below you can find our example implementation in action. It's a list of personal projects, and in this example, we create, update and list our Firestore documents without having a single reference to Firestore classes on our application's layer. No matter how big your project gets, you'll only need to reference Firestore (or the DB of your preference) in two files. All your other UI, data transport, and view model classes will only deal with plain Swift files.
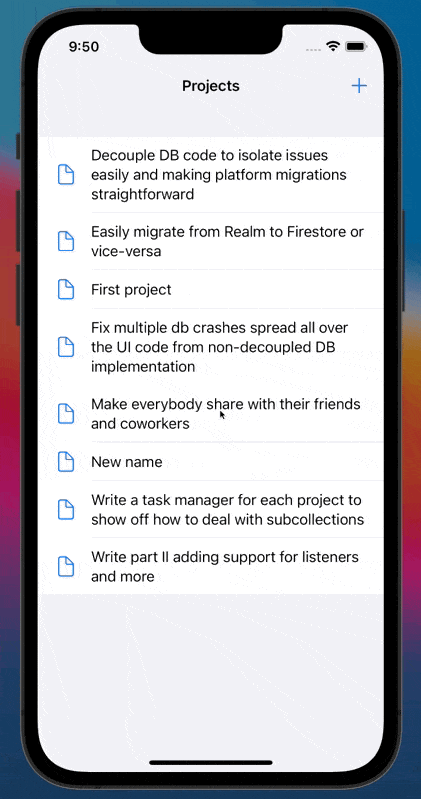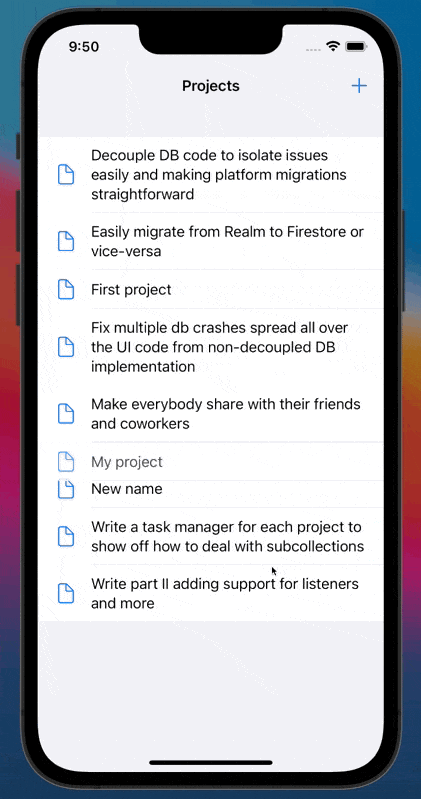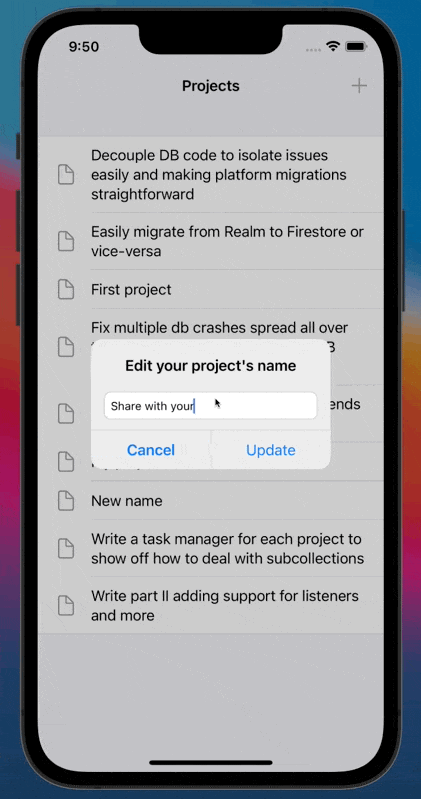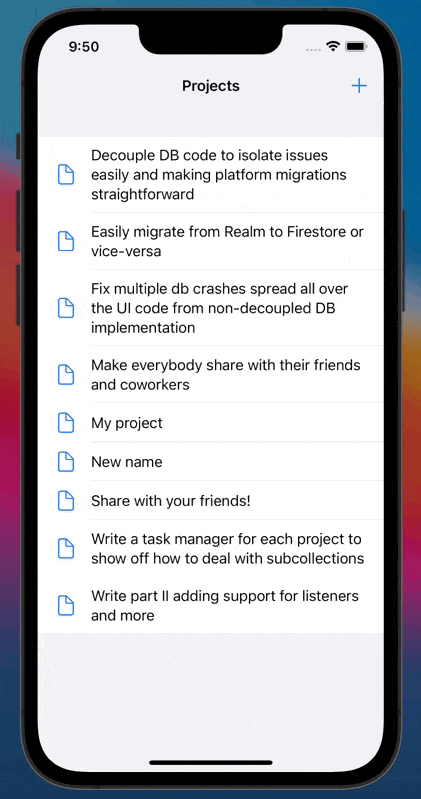
|
|
https://github.com/filipealva/FirestoreProjects |
Some benefits of this approach:
- It makes it way easier to identify database-related issues. You won't get a crash into ProjectDetailsViewController because of an exception when trying to edit a field. Any issue related to your database provider will be contained to the two classes that compound our isolated database layer.
- If you ever need to migrate to another database provider, you'll only need to worry about these two classes. You won't need to go through all the files that do database operations to change the implementation and remove imports. Your database layer will work the very same way. You'll only need to adapt the CRUD operations inside these two small files.
- It's straightforward to extend your database provider functionality. Since all data flowing between your application domain and your database provider goes through your database layer, you can extend or change how queries and listeners work, adding latency or deciding which update will be propagated to your application and which isn't.
How it has started
By the time I started researching this topic, I was mainly working with Realm. I found this fantastic article by Guille Gonzalez, about decoupling Realm database code and mapping it into Swift structs.
I just loved the idea, and it stuck in my mind until the day that I had to write an app from scratch again. The approach I've created for decoupling Firestore is based on the great ideas shared by Guille in his post. This approach worked with Realm, and the fact that porting it to Firestore was quite simple shows how solid it is. Thank you for sharing this and other great pieces of content with the community, Guille!
Creating a mapping structure that fits Firestore
Unlike other mobile database platforms such as CoreData and Realm, Firestore doesn't require you to work with managed objects. It exposes you to the actual document snapshot that holds the data read from a document stored in the database. This is great because you can get the data in the format of a dictionary straight from the result of a query; it makes mapping even smoother.
Another point specific to Firestore, which we must keep in mind while modeling our mapping structure, is that the data in the database is modeled hierarchically. What's important for our context is that each document has a path that plays an essential role in reading and writing data to the document. The hierarchical data structure means that sometimes an approach will require external data to be compound (e.g., its parent identifier), so we need to enable this dynamically path building into our mapping structure.
Persistable protocol
We will use the Persistable protocol as the structure that maps from the Firestore layer to our application layer and vice-versa. We can start by writing the essential components of this protocol, as you can see below:

|
|
|
Our first version of the Persistable is very basic, we start by requiring the following items for every Persistable model:
- An identifier, for obvious reasons;
- A collectionPath, in order to dynamically build the path of the document that a Persistable model will represent;
- An init method that receives a dictionary from the DocumentSnapshot's data property;
- A function that transforms the model into a dictionary to give us the ability to write this data to Firestore.
Database wrapper
Now that we already have our Persistable protocol defined let's work on a basic version of our Database wrapper. This is an essential part of decoupling our database layer because it will execute all the read and write operations which means that it will communicate directly with Firestore. The goal here is to make sure that only the files that handle write and read operations have mentions to Firebase/Firestore types and functions, keeping our application layer free of third-party database code. (Spoiler: there'll be only two classes referring to Firebase/Firestore when we finish the whole thing).

|
There we go; we have the first version of our Database wrapper in place. We call it DatabaseManager, by the way. As you can see, it defines a property that references the singleton instance of Firestore and has a function that handles any write operation we might want to do by using a companion class called WriteTransaction. We are going to explore this class next.
WriteTransaction
The WriteTransaction class is just a companion class for DatabaseManager. It manages all the write operations, and we'll never access it directly, only through the write function we've seen in the last section.

|
As with all other components we've seen until now, this is the elementary version of the WriteTransaction class. It holds a reference for the Firestore instance that it receives from the DatabaseManager at init time and has a function that takes a Persistable value and writes it to a Firestore document using its collectionPath and its identifier.
Hands on!
After going through the very basics of our structure, let's start playing with a demo project to apply what we've already seen and add more features to our decoupled database layer. You can find the source code of the project that we will use at https://github.com/filipealva/FirestoreProjects.
As the name suggests, our demo project will be a simple app that stores a list of projects in a root collection. Each document stored inside this root collection, which we'll call "projects," will hold a sub-collection that will store a list of tasks. We call this sub-collection "tasks".
With the requirements described above, we'll be able to show how to interact with most features of Firestore using our decoupled database layer.
IMPORTANT: The demo project doesn't contain the GoogleService-Info.plist file, which is needed for everything to work correctly. You'll need to sign in to Firebase and create your project there. Inside your project's settings, you'll need to add your iOS app and run all the instructions for setting up your own Firebase instance.
You can follow all the steps here without actually reproducing them, but I would recommend you to do so and play out with this demo project. It's a lot of fun :)
Creating a document
We will start by creating our first document into the Firestore database. If you are running the demo project with your own Firebase instance, make sure to set up the development environment security rules (or customize them in a way that you'll be able to write from a client, if you'd like to), and also to create the root collection called "projects".

|
Above, you can see our Project model after adopting the Persistable protocol. It's a straightforward implementation; we could use Codable here and even handle the default values better, but let's focus on handling the database layer for now. You can also notice that we have an extra init method that takes a name to create a new instance of a Project. We'll use this init to create a new project inside our application.
We are already able to write our first project to the Firestore database. Before actually doing that, we will cover how to query for all the projects stored so we can present the projects as soon as we read them. Still, if you're curious enough and want to add your first project right now, you can add the piece of code below anywhere, and it will do the job.
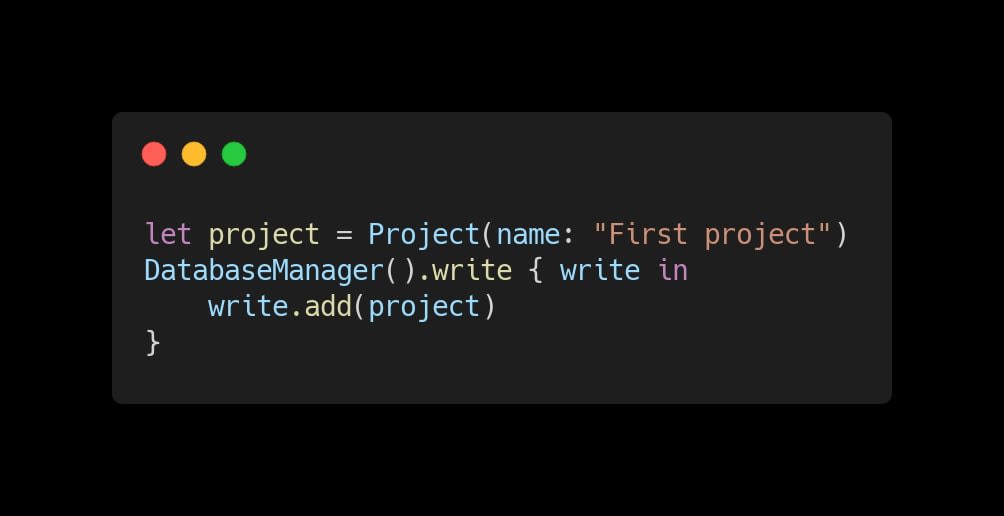
|
Reading documents
We wrap Firestore's querying mechanism by combining NSPredicate and NSSortDescriptor. Most of the other database platforms provide a way to query using these Foundation querying features, so it adds up to our ability to easily switch to another database provider while keeping the same (or almost the same) wrapper. We do that by requiring them in our internal query protocol called QueryType. Below you can see what this protocol looks like.
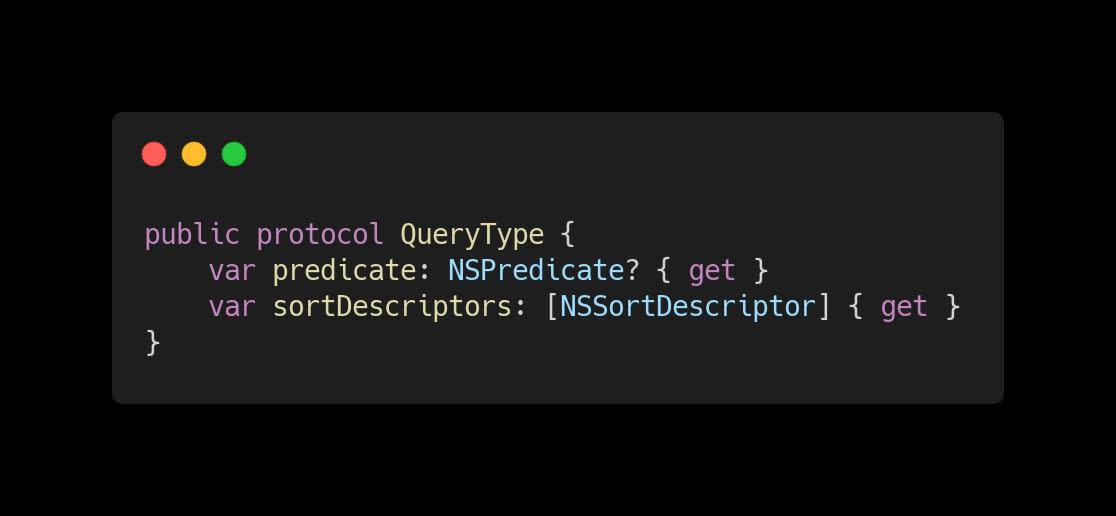
|
After defining QueryType, we create a default implementation that returns nil for the NSPredicate and an empty list of NSSortDescriptors, we call this default implementation DefaultQuery, and the purpose of it is to act as a default value in the definition of QueryType inside the Persistable protocol, as you can see in the code below.
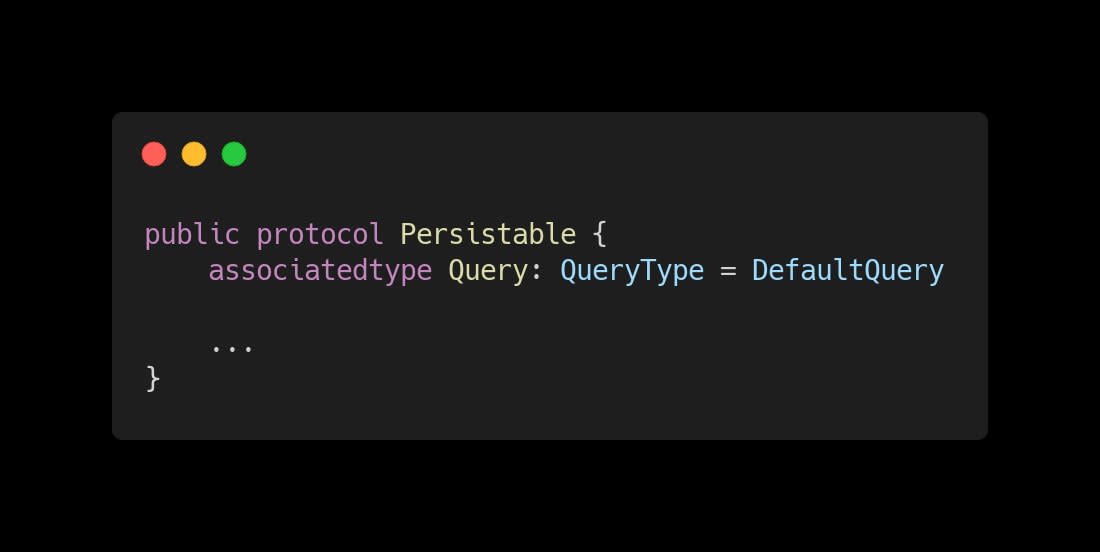
|
Fetching values
Below you can find a breakdown of our method that fetches the data from Firestore. We will go through all those steps in the following sections of this post.
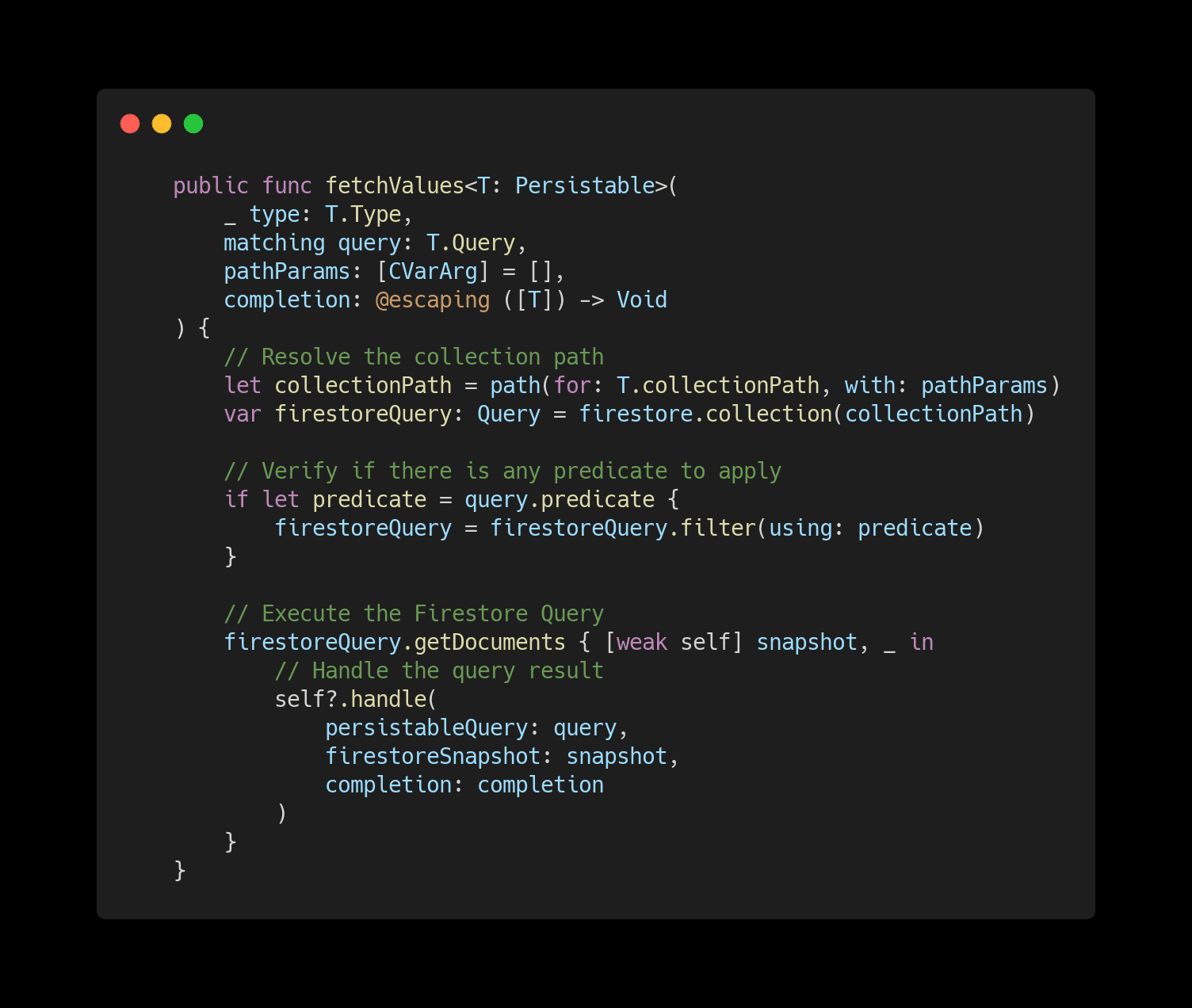
|
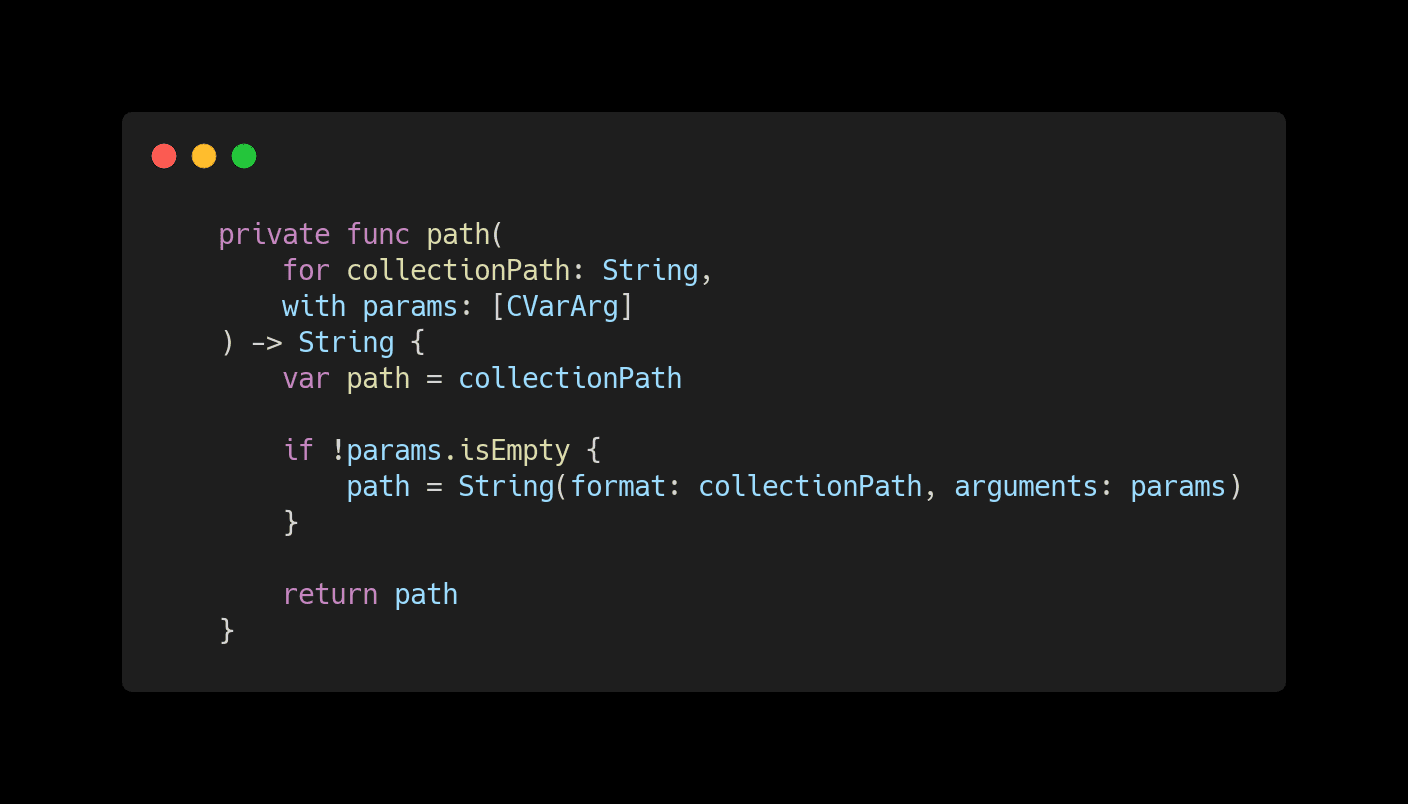
Remember when I said that because of the hierarchical nature of Firestore, we would have to deal with compound collection paths? Here is an example of that. Our method receives the Persistable type, and an array of parameters is used to resolve this compound path.
The projects collection is a root collection, so that we won't see it in action in this first example. Yet let's cover how it works, so we are ready for it when we deal with a sub-collection in the future.
|
As you can see, it's a straightforward method that checks if there's any parameter to be resolved, and if so, it binds it within the collection path that must have been set with the proper string placeholders. Then the compound collection path is returned, and it's ready to be used.
After resolving the collection path, we verify if the Persistable Query has any predicate. If it has, we add it to the Firestore Query by using the filter(using: NSPredicate) method. Then we execute the query through the getDocuments call, which takes a closure as a parameter to provide us with the query results.
Handling the results of a query
In the last section, we ended our code by calling a method to handle the query results we just executed. Below you can find the breakdown of this method call.
|
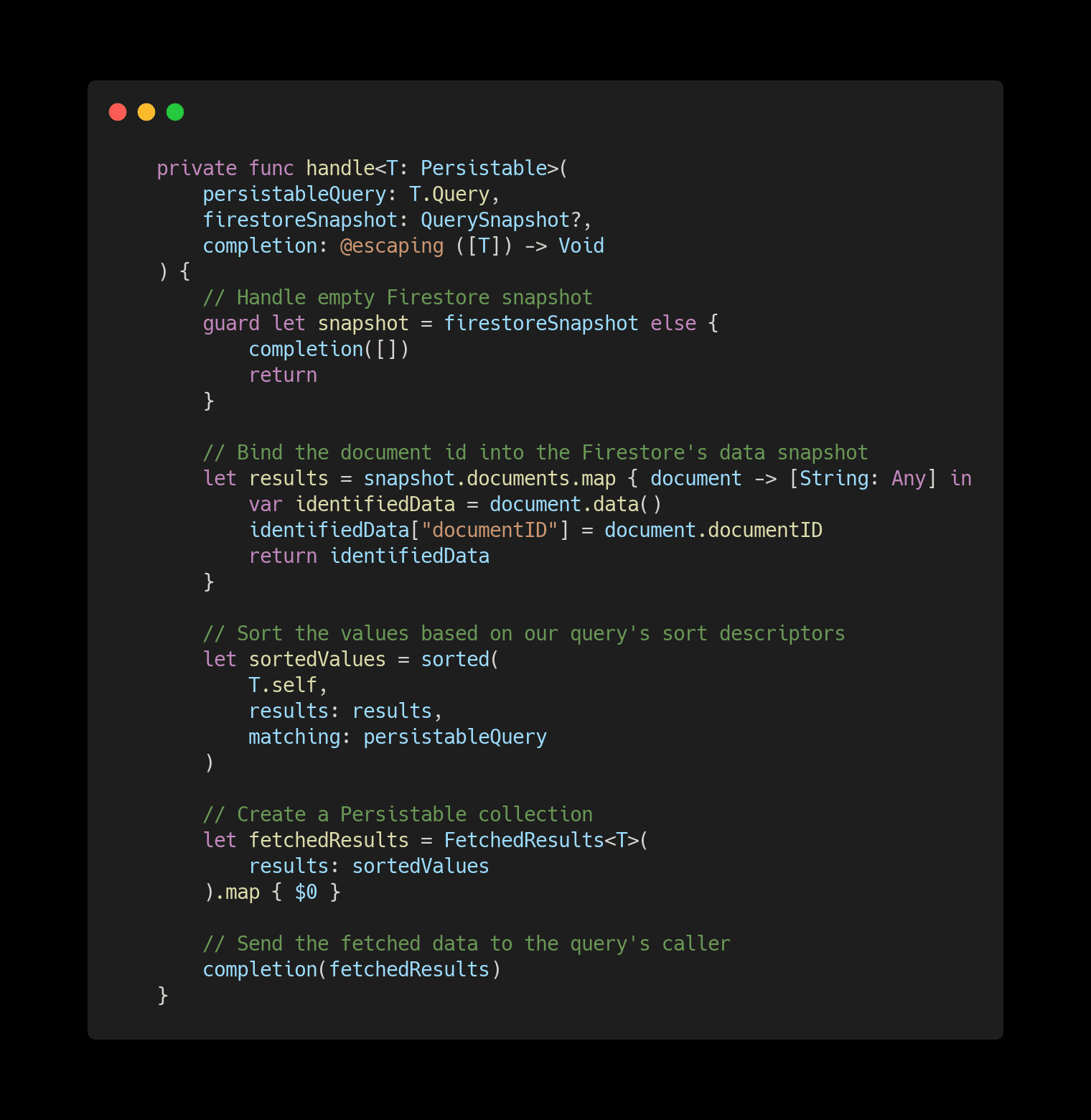
We start by making sure that there is a Firestore Query snapshot. If there's none, we'll return an empty list for now.
We bind the document identifier into the Firestore's document snapshot dictionary in the next step. Document snapshots are easily convertible into regular structs or classes because they provide a dictionary containing all the fields and their respective values. The only issue is that this dictionary doesn't provide the document identifier. The solution is mapping through the document snapshots and adding the document identifier from the actual Document to them. Then, we have all the information needed to map the dictionary into a Peristable struct.
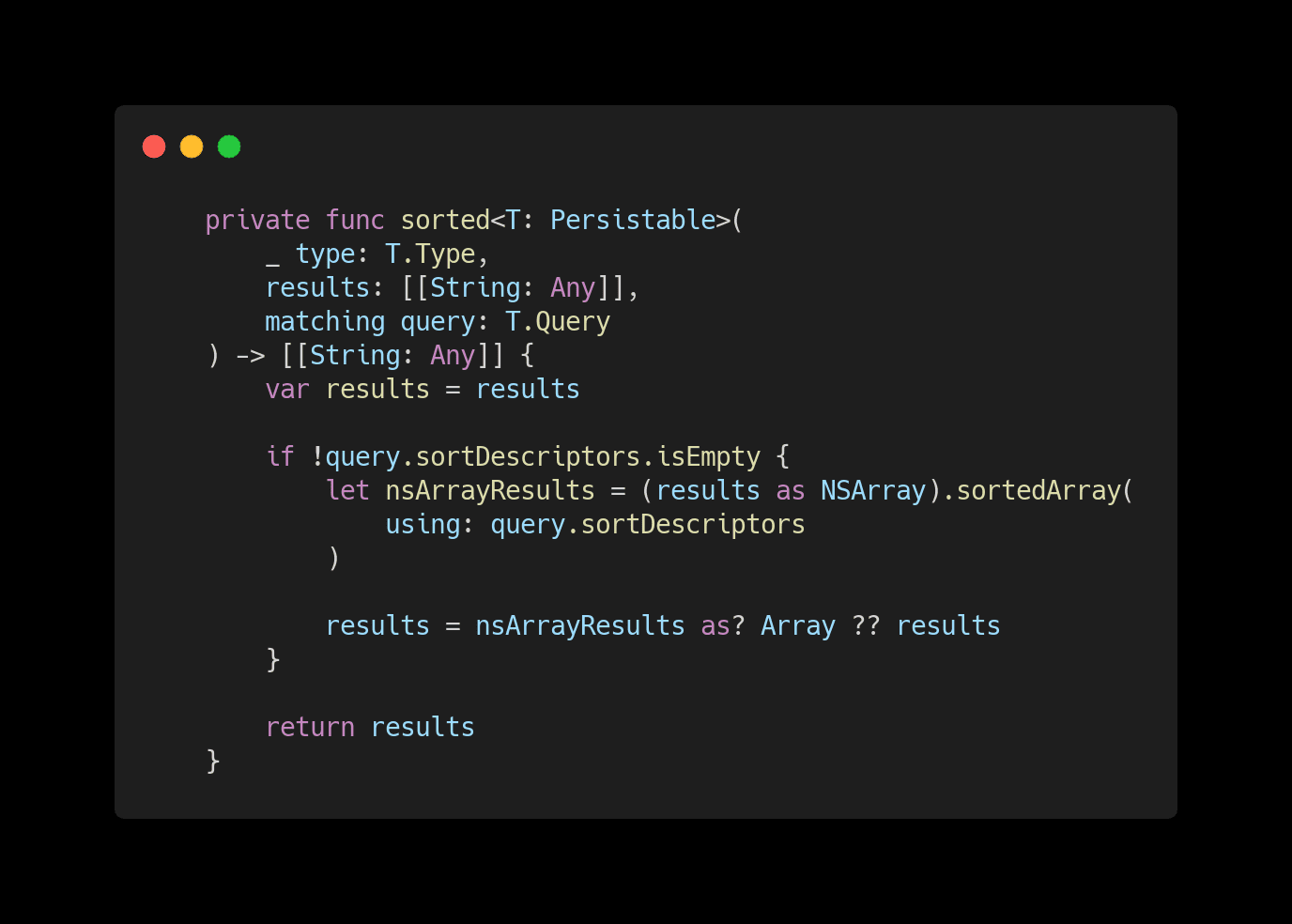
Now that we have all the data, we can apply our sort descriptors. As seen below that's done by using our Persistable Query's sort descriptors into an NSArray of dictionaries.
|
With the sorted data in hand, the last step before providing our query results is creating a list of Persistable items. It would be nice to use an Array, but we can't because the Persistable protocol has associated type requirements. So, we need to create a new class that takes a list of dictionaries and can transform it into a list of Persistable items.
Although it might seem complicated, it's a very straightforward operation. You can check the class named FecthedResults on the demo project to understand more. Thanks to this class, we can pass an array of Projects to the completion closure without having to instantiate any Project explicitly.
That's all for the query implementation. After that, you'll only need one call to query for all the projects, as seen below.

|
Updating documents
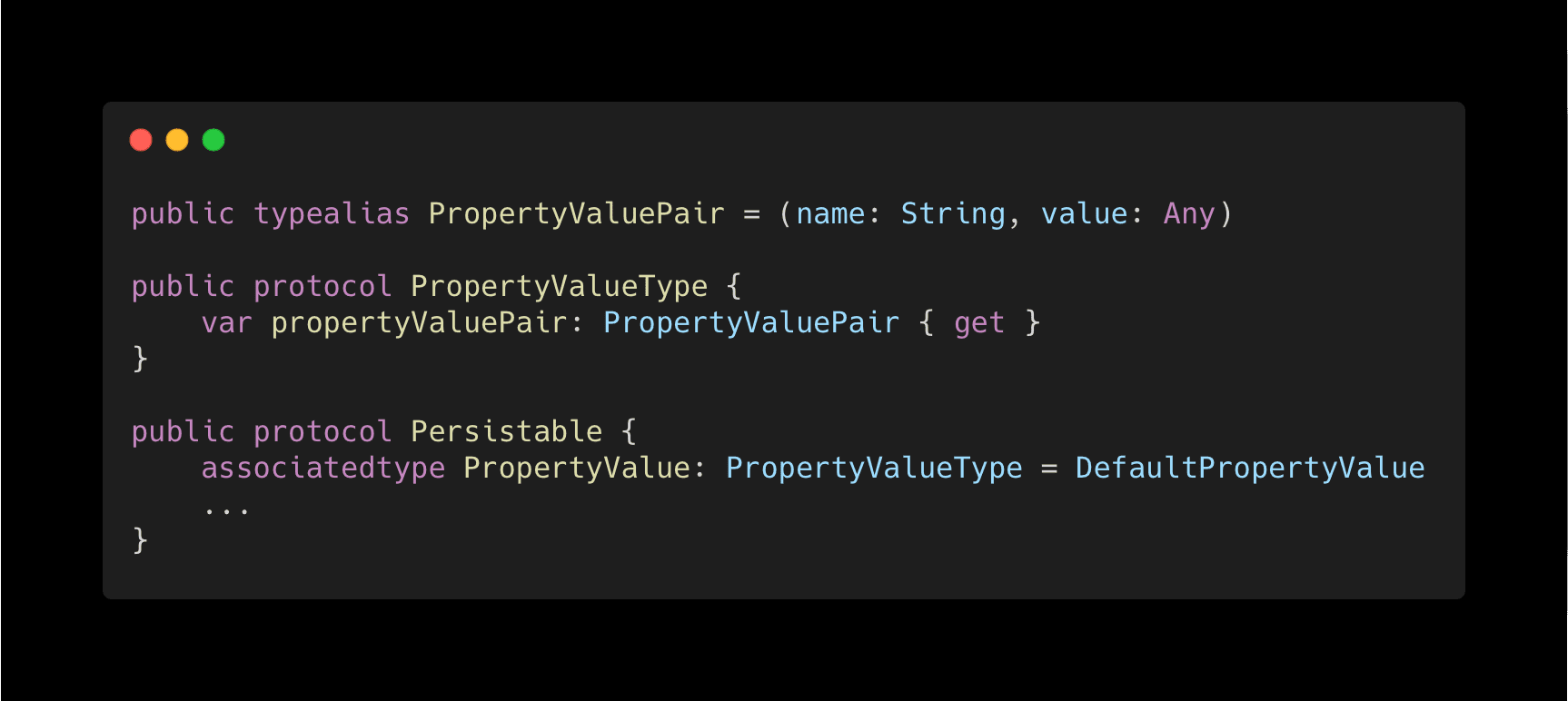
The last topic we'll cover in this part is updating a document. To accomplish that, the first step is to add our PropertyValue associated type to the Persistable protocol. It's a tuple containing a pair of each field that can be updated in the document and its value.
|
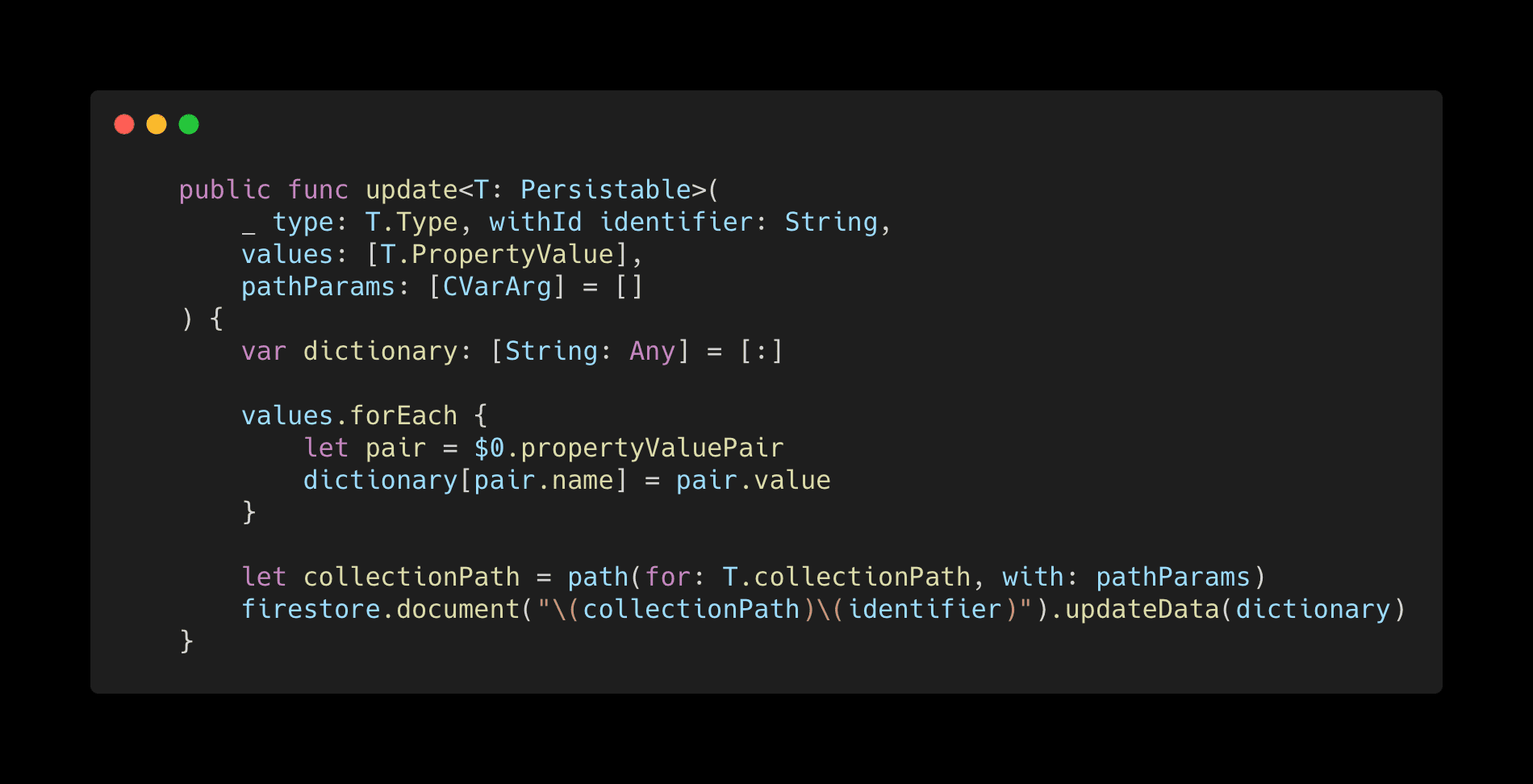
Now that all our Persistable entities have a field-value pair of all fields that can be updated, we need to implement the update functionality on our WriteTransaction class. It will take a Persistable type, its identifier, and a list of fields that should be updated along with their new values.
|
The method takes the parameters mentioned above and iterates through them, creating a dictionary of fields and their new values. Then we call the Firestore method that handles the update.
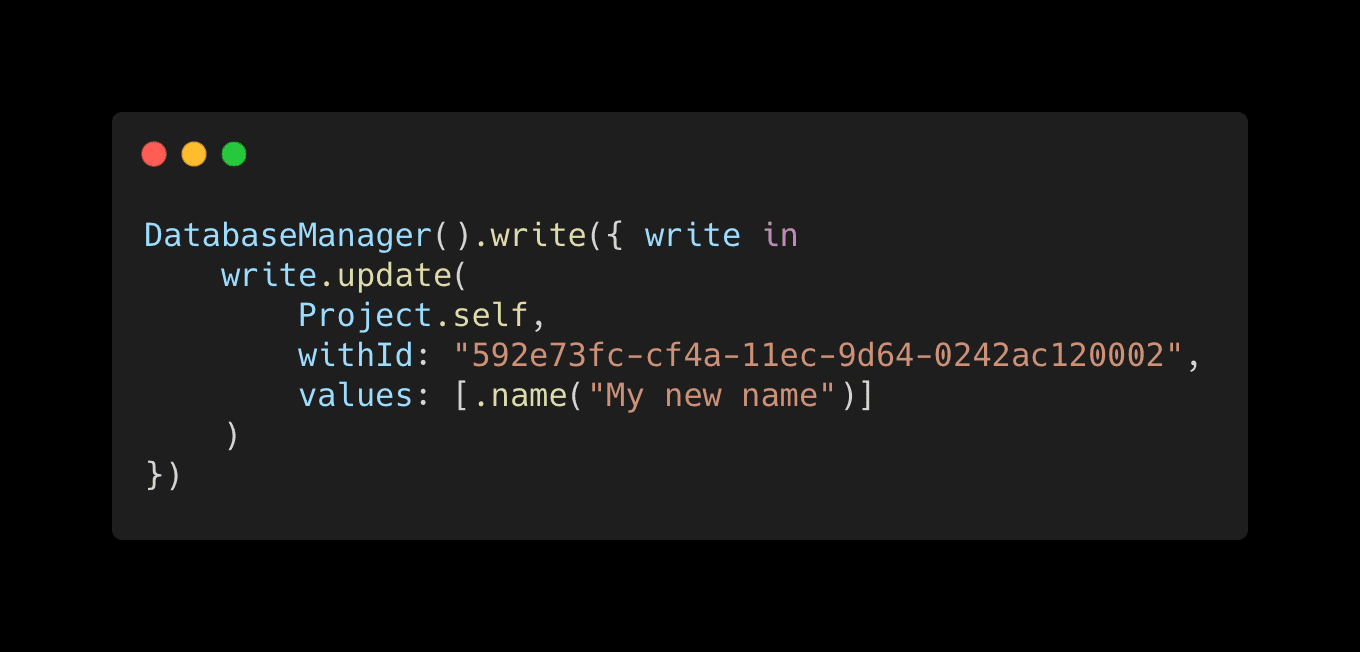
Then you can use the plain Swift call below all over your project without exposing Firestore to the class that's calling it.
|
Let's practice!
Now that we did cover how to create, read and update documents using our decoupled database layer, you can download our example project and play around with it. You can find the link below.
https://github.com/filipealva/FirestoreProjects
Conclusion
Your project can have thousands of files in real life, and only two files will know about Firestore. With the example project, you'll see that it's straightforward to maintain the database layer. It reduces the complexity of the other application layers because they deal with simple structs instead of Firestore types and operations, making it easier for a possible database provider migration.
Please share it with your friends and coworkers if you liked the content. If you have any questions or want to request part 2, where I'll cover listeners and other operations, leave me a DM on Twitter.